What
非关系型数据库
- 高可靠性
- 高性能
- 面向列
- 可伸缩
- 实时读写
- 分布式
对比
- 关系型数据库的优点
- 容易理解
- 使用方便
- 易于维护
- 关系型数据库的瓶颈
- 高并发读写需求
- 海量数据的读写性能低
- 扩展性和可用性差

数据库模型
-
row key
- 不能重复
- 字典顺序排序
- 只能存储64k的字节
-
列族
- 小于等于3个
-
列名
- 以列族作为前缀
- 可动态加入
-
celll单元格
- 有版本
- 字节数组
1
{row key, column( =<family> +<qualifier>), version}
-
时间戳
- 默认是1
- 时间倒序排序,最新最前
- 64位整型
- 默认精确到毫秒,可以主动设置
-
Hlog (wal log)
- HLogkey 数据归属信息
- table
- region
- sequence number
- timestamp
- value
- 就是hbase的 keyvale对象
- HLogkey 数据归属信息
体系架构
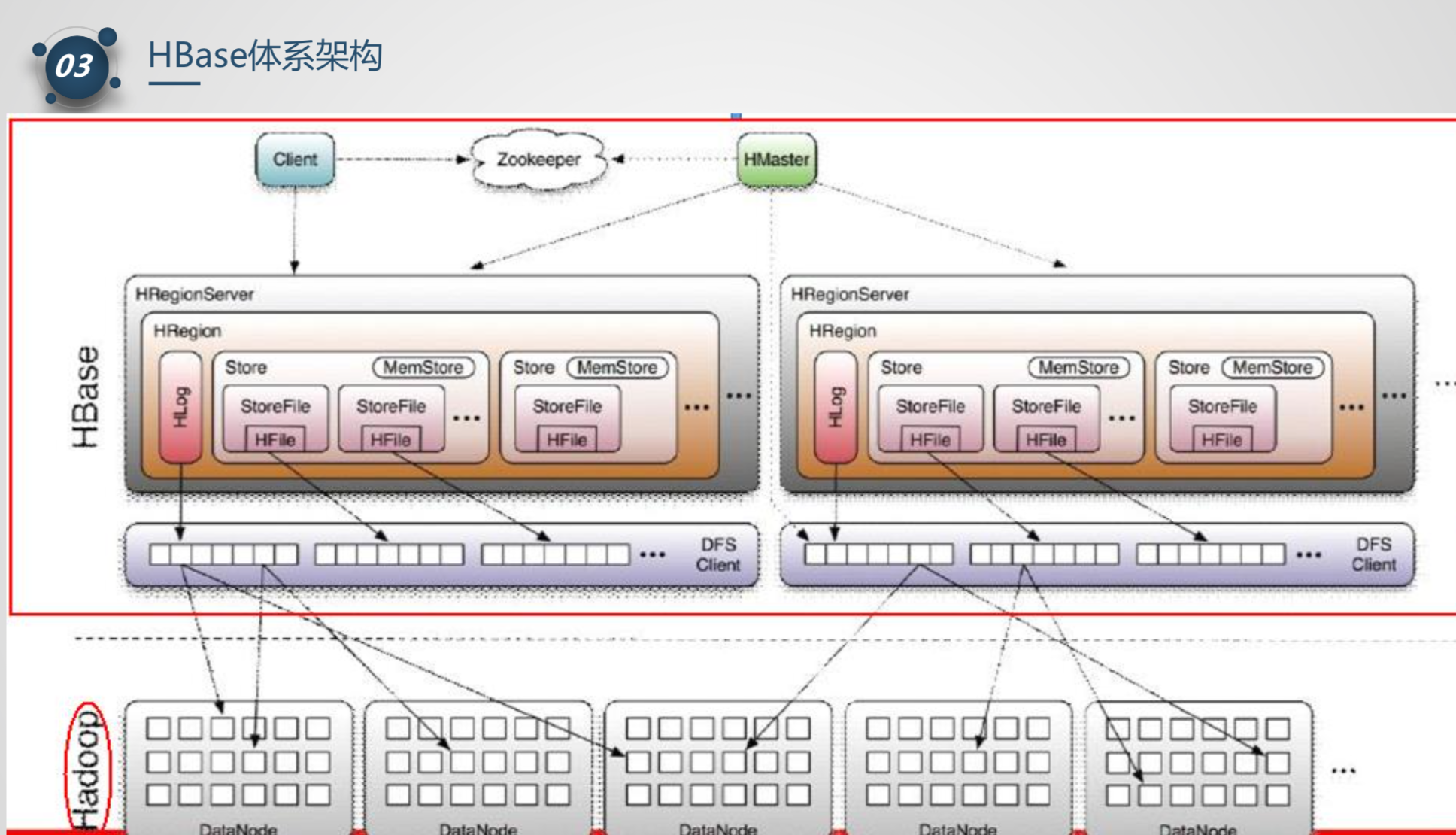
- client
- zookeeper
- 保证集群只有一个master
- 存储 region的寻址入口
- 监控region
- master
- 负责负载均衡
- 发现失效region server 重新分配region
- 管理用户CRUD
- Region server
- 维护region
- region
- d
- store 一个store对应一个CF(列族)
- memstore
- storefile
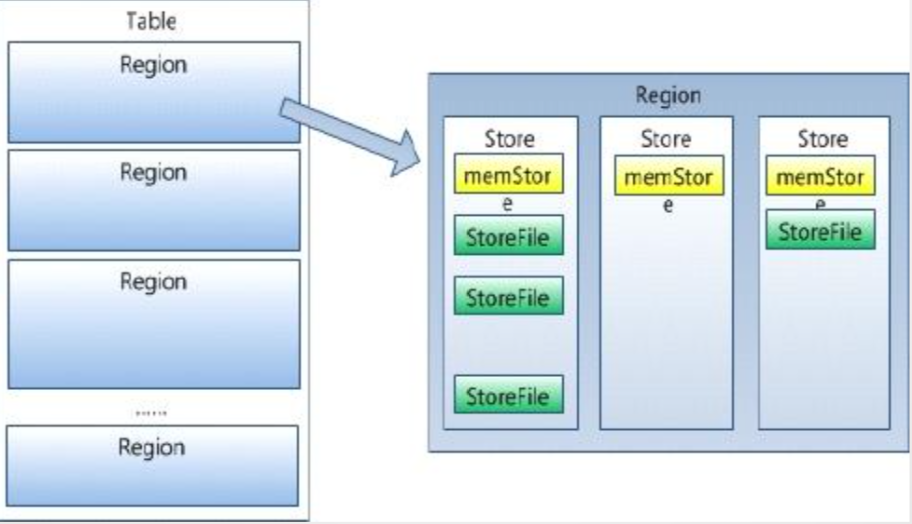
高表与宽表的选择
- 查询性能 高表更好
- 分片能力 高表更细
- 元数据开发 高表更大 rowkey 多,region 多 meta 数据量大
- 事务能力 宽表事务性更好
- 数据压缩比 宽表更高
Where
http://hbase.apache.org
Why
How
squirrel sql client
-
cd /opt/soft -
wget http://mirrors.cnnic.cn/apache/hbase/0.98.24/hbase-0.98.24-hadoop2-bin.tar.gz -
tar zxvf hbase-0.98.24-hadoop2-bin.tar.gz -
vi ~/.bash_profile增加1
2export HBASE_HOME=/app/hbase-0.96.2
export PATH=$PATH:$HBASE_HOME/bin发送打其它节点
1
2scp ~/.bash_profile root@sj-node2:/root
scp ~/.bash_profile root@sj-node3:/root -
source ~/.bash_profile生效 -
vi /opt/soft/hbase-0.98.24-hadoop2/conf/hbase-env.sh修改1
2
3export JAVA_HOME=/opt/soft/jdk1.7.0_25
export HBASE_CLASSPATH=/opt/soft/hadoop-2.5.1
export HBASE_MANAGES_ZK=false -
vim /opt/soft/hbase-0.98.24-hadoop2/conf/hbase-site.xml1
2
3
4
5
6
7
8
9
10
11
12<property>
<name>hbase.rootdir</name>
<value>hdfs://appcity:8020/hbase</value>
</property>
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<property>
<name>hbase.zookeeper.quorum</name>
<value>sj-node1,sj-node2,sj-node3</value>
</property> -
vim /opt/soft/hbase-0.98.24-hadoop2/conf/regionservers1
2sj-node1
sj-node2 -
vim /opt/soft/hbase-0.98.24-hadoop2/conf/backup-masters1
sj-node2
-
拷贝hdfs的配置文件到hbase配置目录下
cp /opt/soft/hadoop-2.5.1/etc/hadoop/hdfs-site.xml /opt/soft/hbase-0.98.24-hadoop2/conf/ -
将配置好的hbase发送到其它节点
scp -r /opt/soft/hbase-0.98.24-hadoop2 root@sj-node2:/opt/soft/scp -r /opt/soft/hbase-0.98.24-hadoop2 root@sj-node3:/opt/soft/ -
在sj-node1节点上启动
start-hbase.sh -
在webL浏览器访问 http://sj-node1:60010
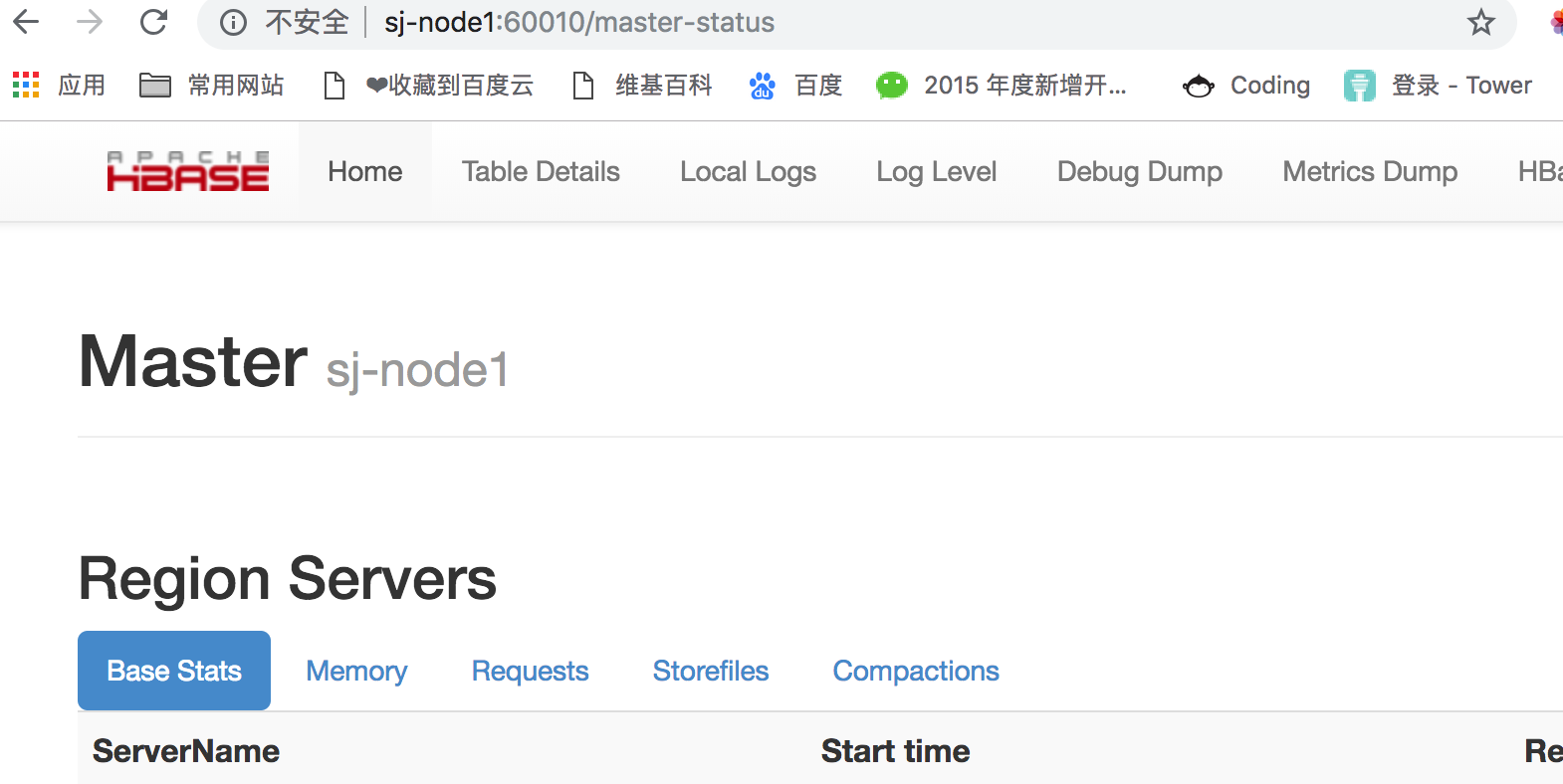
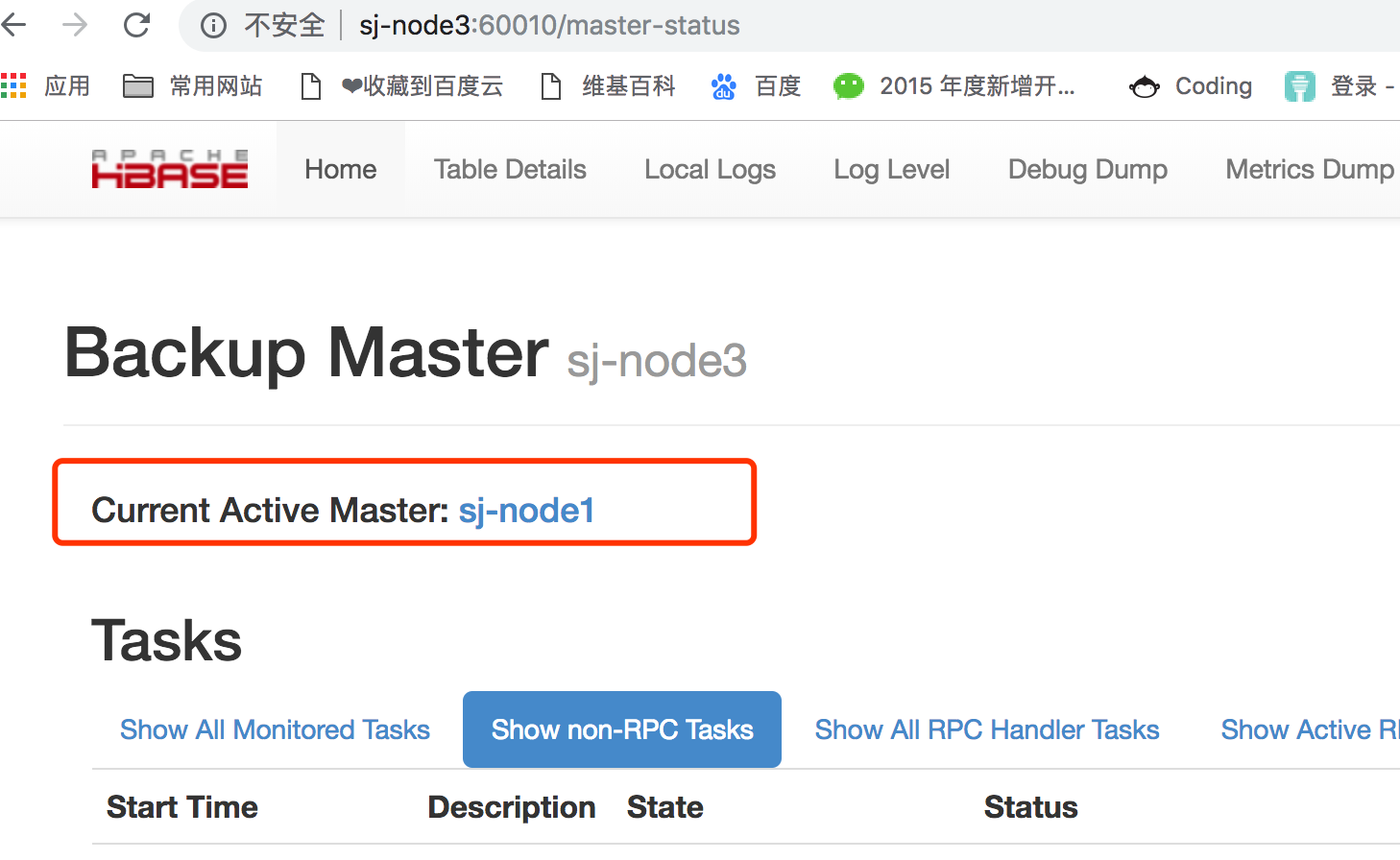
-
试下ha高可用 kill 调用sj-node1上的master 自动切换完成

 重新启动sj-node1节点 的hbase则变为backup
重新启动sj-node1节点 的hbase则变为backup

命令
- 打开命令行
hbase shell helplistcreate 'testhbase','cf1'put 'testhbase','rk00001','cf1:id','001'scan 'testhbase'get 'testhbase','rk00001'disable 'testhbasedelete 'testhbase','rk00001','cf1:id'
预分区
在创建HBase表的时候默认一张表只有一个region,所有的put操作都会往这一个region中填充数据,当这个一个region过大时就会进行split。如果在创建HBase的时候就进行预分区则会减少当数据量猛增时由于region split带来的资源消耗。
create 'testsplit','cf1',SPLITS => ['000','100','200']put 'testsplit','002','cf1:id','002d'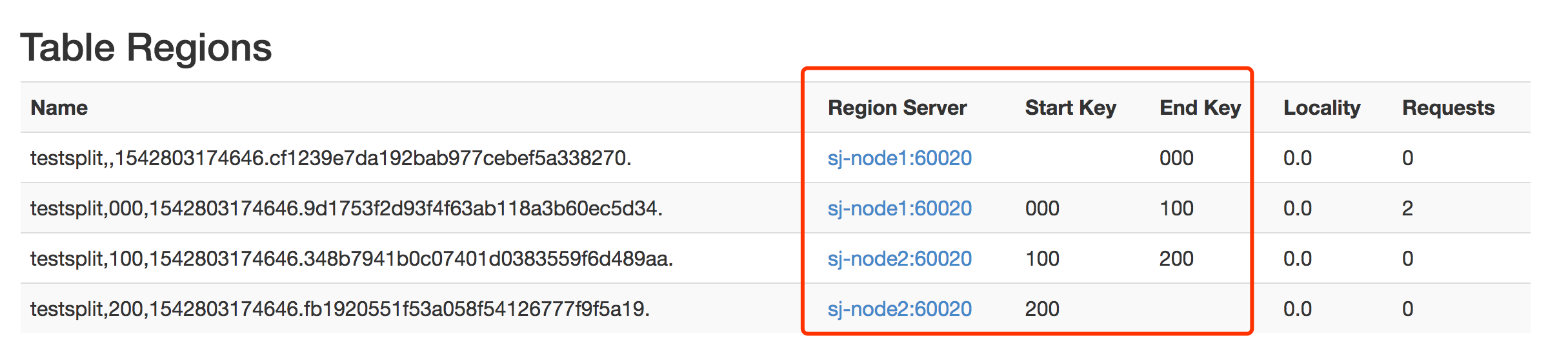
java api
-
rowkey 设计
-
创建删除表
-
put 数据 单个或多个
-
get 数据
-
scan
- 起始row 终止row
- 过滤器
- 前缀
- 列值(字符串比较)
-
中文乱码
- new String(rs.getRow(),"utf-8")
- Bytes.toString(CellUtil.cloneValue(cell).replace("\x","%"),"utf-8")
优化
- 表的设计
- 预分区
- row key
- 长度原则 定长 越小越好 2的幂次方
- 散列性 取反 hash 高位随机串
- 唯一性 保证key的唯一
- 根据实际业务来
- 列族不能超过3个
- setinmemory 大部分能提高效率
- TTL 存储时长
- compaction 合并默认值
- majorcompaction =24
- jetter = 0.2
- 写表操作
- 多表同时写
- htable参数设置
- auto flush
- write buffer
- wal
- 批量写
- 多线程并发写 map reduce 写
- 读表操作
- 多htable 并发读
- scan 指定列族
- 关闭result
- 批量读
- blockcache
