What
storm是个实时的,分布式,高容错的计算系统
- storm进程常驻内存
- strom数据不经过磁盘,在内存中处理 <!-- more -->
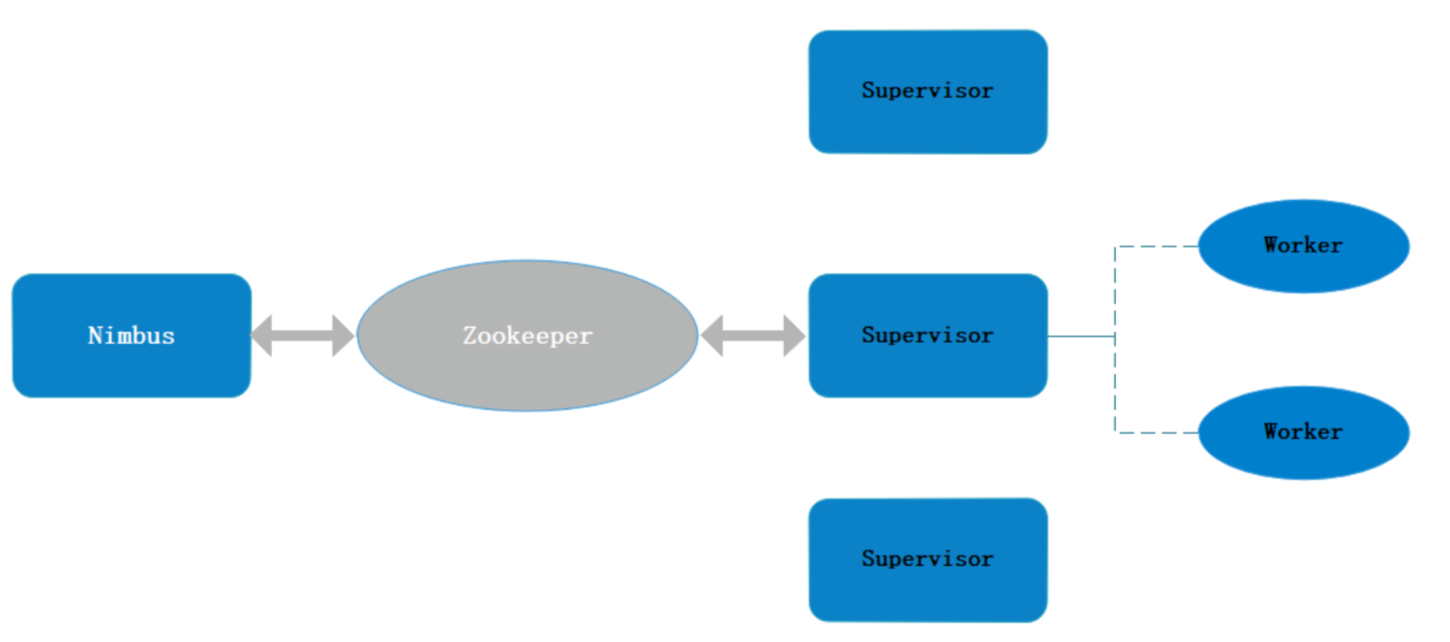
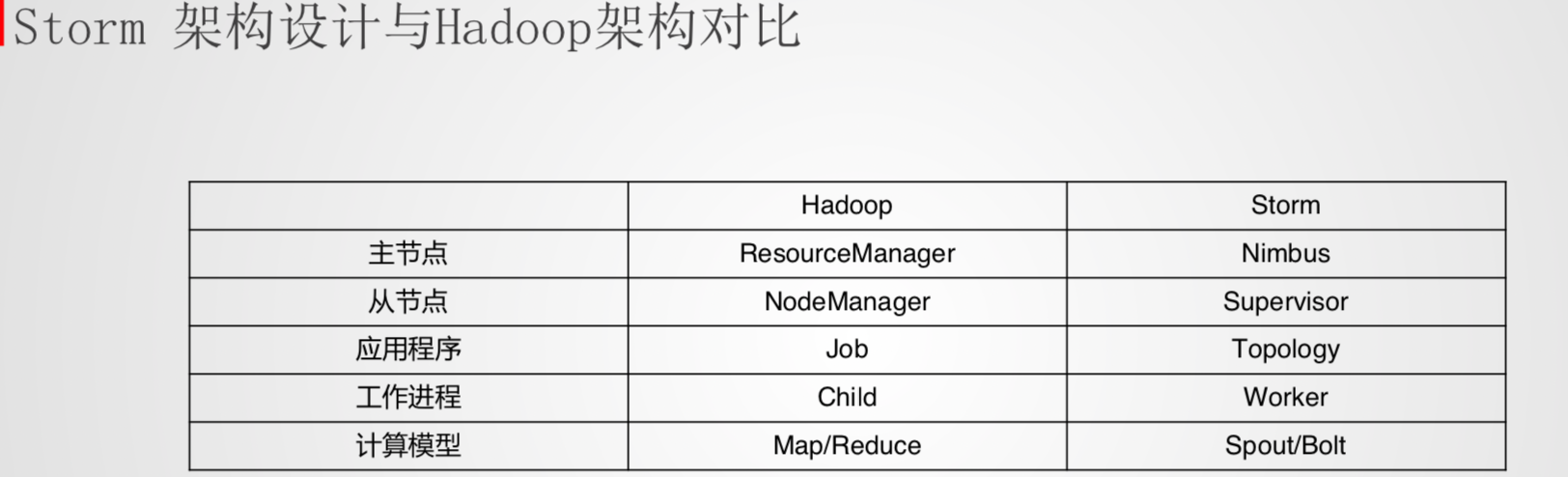
架构
- Nimbus
- 资源调度
- 任务分配
- 接收jar包
- Supervisor
- 接收nimbus分配的任务
- 启动、停止自己管理的worker进程(当前supervisor上worker数量由配置文件设定)
- Worker
- 运行具体处理运算组件的进程(每个Worker对应执行一个Topology的子集)
- worker任务类型,即spout任务、bolt任务两种
- 启动executor
(executor即worker JVM进程中的一个java线程,一般默认每个executor负责执行一个task任务)
编程模型
- DAG
- Spout数据源
- Bolt数据流处理组件
数据分发策略 storm grouping
- Shuffle grouping
- 随机分组,随机派发stream里面的tuple,保证每个bolt task接收到的tuple数目大致相同。
- 轮询,平均分配
- Fields Grouping
- 按字段分组,比如,按"user-id"这个字段来分组,那么具有同样"user-id"的 tuple 会被分到相同的Bolt里的一 个task, 而不同的"user-id"则可能会被分配到不同的task。
- None Grouping 不分组,这个分组的意思是说stream不关心到底怎样分组。目前这种分组和Shuffle grouping是一样的效果
- All Grouping 广播发送,对于每一个tuple,所有的bolts都会收到
- Global Grouping 全局分组,把tuple分配给task id最低的task 。
- Direct Grouping 指向型分组, 这是一种比较特别的分组方法,用这种分组意味着消息(tuple)的发送者指定由消息接收者的 哪个task处理这个消息。只有被声明为 Direct Stream 的消息流可以声明这种分组方法。而且这种消息tuple必 须使用 emitDirect 方法来发射。消息处理者可以通过 TopologyContext 来获取处理它的消息的task的id (OutputCollector.emit方法也会返回task的id)
- Local or shuffle grouping 本地或随机分组。如果目标bolt有一个或者多个task与源bolt的task在同一个工作进程中,tuple将会被随机发 送给这些同进程中的tasks。否则,和普通的Shuffle Grouping行为一致
- customGouping 自定义,相当于mapreduce那里自己去实现一个partition一样。
计算模型
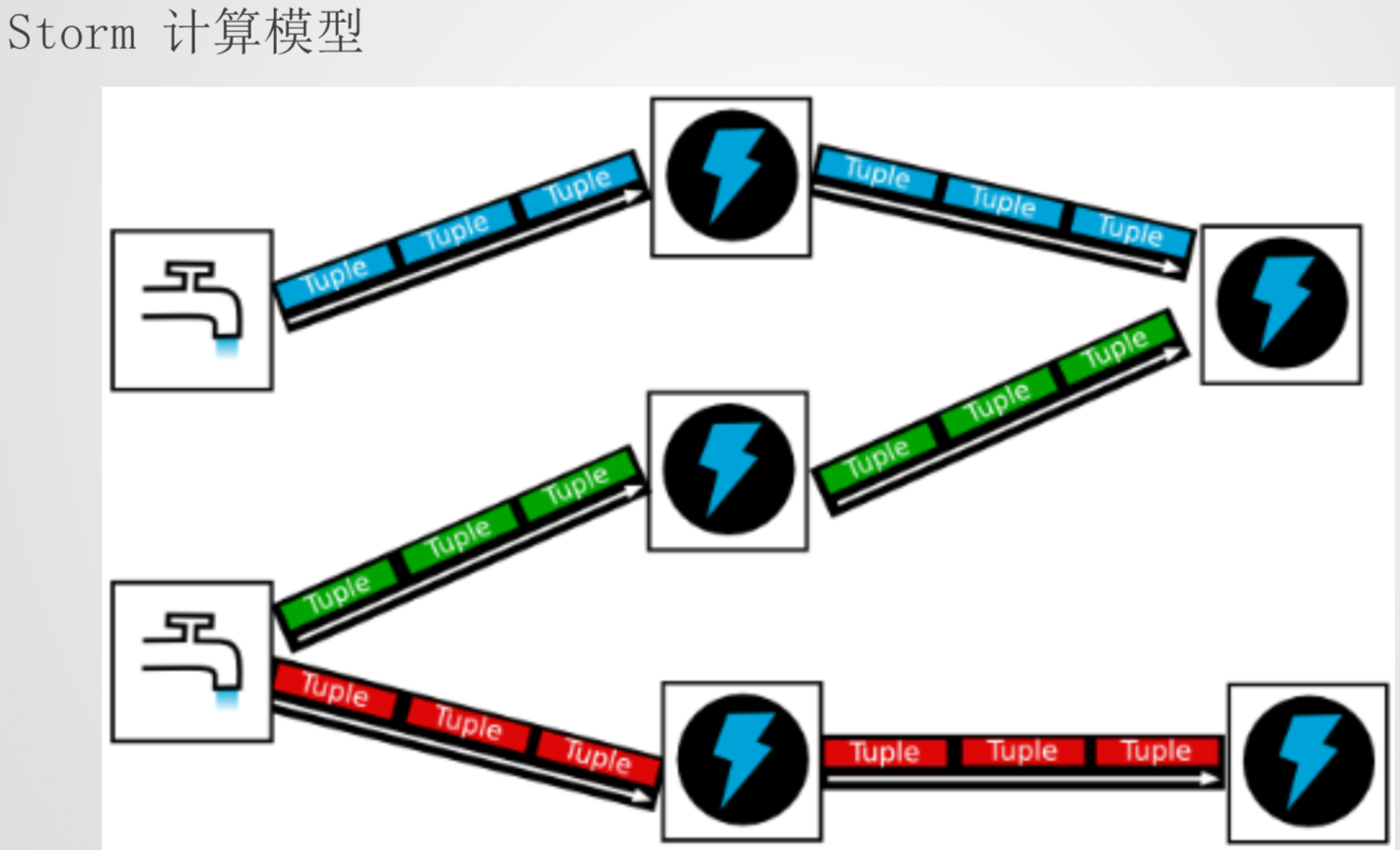
- Topology– DAG有向无环图的实现
- 对于Storm实时计算逻辑的封装
- 即,由一系列通过数据流相互关联的Spout、Bolt所组成的拓扑结构
- 生命周期:此拓扑只要启动就会一直在集群中运行,直到手动将其kill,否则不会终止 (区别于MapReduce当中的Job,MR当中的Job在计算执行完成就会终止)
- Tuple – 元组 Stream中最小数据组成单元
- Stream – 数据流
- 从Spout中源源不断传递数据给Bolt、以及上一个Bolt传递数据给下一个Bolt,所形成的这些数据通道即叫做 Stream
- Stream声明时需给其指定一个Id(默认为Default)
- 实际开发场景中,多使用单一数据流,此时不需要单独指定StreamId
- Spout – 数据源
- 拓扑中数据流的来源。一般会从指定外部的数据源读取元组(Tuple)发送到拓扑(Topology)中
- 一个Spout可以发送多个数据流(Stream)
- 可先通过OutputFieldsDeclarer中的declare方法声明定义的不同数据流,发送数据时通过SpoutOutputCollector中的 emit方法指定数据流Id(streamId)参数将数据发送出去
- Spout中最核心的方法是nextTuple,该方法会被Storm线程不断调用、主动从数据源拉取数据,再通过emit 方法将数据生成元组(Tuple)发送给之后的Bolt计算
- Bolt – 数据流处理组件
- 拓扑中数据处理均有Bolt完成。对于简单的任务或者数据流转换,单个Bolt可以简单实现;更加复杂场景往往 需要多个Bolt分多个步骤完成
- 一个Bolt可以发送多个数据流(Stream)
- 可先通过OutputFieldsDeclarer中的declare方法声明定义的不同数据流,发送数据时通过SpoutOutputCollector中的 emit方法指定数据流Id(streamId)参数将数据发送出去
- Bolt中最核心的方法是execute方法,该方法负责接收到一个元组(Tuple)数据、真正实现核心的业务逻辑
任务提交流程

storm 并发机制
- worker 进程
- 一个Topology拓扑会包含一个或多个Worker(每个Worker进程只能从属于一个特定的Topology)
- 这些Worker进程会并行跑在集群中不同的服务器上,即一个Topology拓扑其实是由并行运行在Storm集群中 多台服务器上的进程所组成
- 设置Worker进程数
- Config.setNumWorkers(int workers)
- executor 线程
- Executor是由Worker进程中生成的一个线程
- 每个Worker进程中会运行拓扑当中的一个或多个Executor线程
- 一个Executor线程中可以执行一个或多个Task任务(默认每个Executor只执行一个Task任务),但是这些 Task任务都是对应着同一个组件(Spout、Bolt)
- 设置Executor线程数
- TopologyBuilder.setSpout(String id, IRichSpout spout, Number parallelism_hint)
- TopologyBuilder.setBolt(String id, IRichBolt bolt, Number parallelism_hint)
- 其中, parallelism_hint即为executor线程数
- task
- 实际执行数据处理的最小单元
- 每个task即为一个Spout或者一个Bolt
- 设置Task数量
- ComponentConfigurationDeclarer.setNumTasks(Number val)
- Rebalance – 再平衡
- 即,动态调整Topology拓扑的Worker进程数量、以及Executor线程数量
- 通过Storm UI
- 通过Storm CLI
- storm rebalance mytopology -n 5 -e blue-spout=3 -e yellow-bolt=10

- storm rebalance mytopology -n 5 -e blue-spout=3 -e yellow-bolt=10
Task数量在整个Topology生命周期中保持不变,Executor数量可以变化或手动调整 Task数量和Executor是相同的,即每个Executor线程中默认运行一个Task任务
Storm 通信机制
- Worker进程间的数据通信
- Netty
- Worker内部的数据通信
- Disruptor
storm 容错机制
- 集群节点宕机
- Nimbus服务器
- 非Nimbus服务器
- 进程挂掉
- Worker
- 挂掉时,Supervisor会重新启动这个进程。如果启动过程中仍然一直失败,并且无法向Nimbus发送心跳,Nimbus会将该 Worker重新分配到其他服务器上
- Supervisor
- 无状态(所有的状态信息都存放在Zookeeper中来管理)
- 快速失败(每当遇到任何异常情况,都会自动毁灭)
- Nimbus
- 无状态(所有的状态信息都存放在Zookeeper中来管理)
- 快速失败(每当遇到任何异常情况,都会自动毁灭)
- Worker
- Acker -- 消息完整性的实现机制
- Storm的拓扑当中特殊的一些任务
- 负责跟踪每个Spout发出的Tuple的DAG(有向无环图)
Why
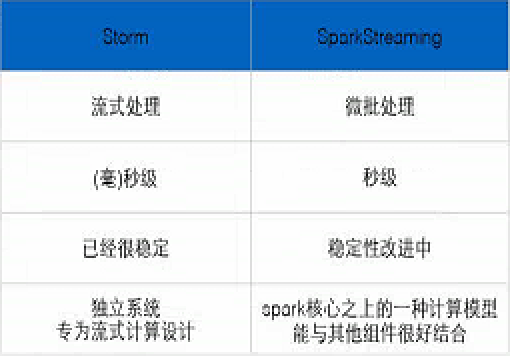
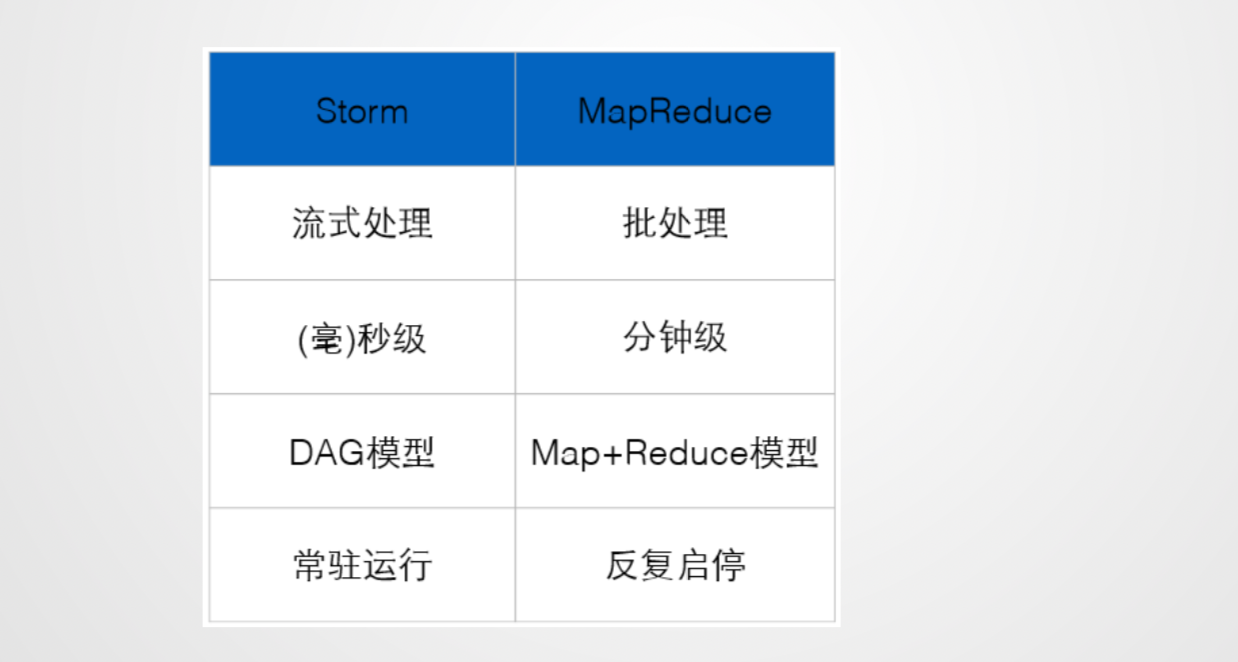
Storm:纯流式处理
- 专门为流式处理设计
- 数据传输模式更为简单,很多地方也更为高效
- 并不是不能做批处理,它也可以来做微批处理,来提高吞吐
Where
http://storm.apache.org
How
完全分布式部署
tar zxvf apache-storm-0.10.0.tar.gz
- 创建日志目录
mkdir logs - 在node1 上执行 bin/storm nimbus > logs/nimbus.out 2>&1 & bin/storm ui > ./logs/ui.out 2>&1 &
- 在node2上执行 bin/storm supervisor > logs/supervisor.out 2>&1 &
- 在node3 上执行 bin/storm supervisor > logs/supervisor.out 2>&1 &
命令:
bin/strom supervisor > logs/supervisor.out 2 >&1 &
bin/strom --help
bin/strom rebalance wc -w 5 -n 3 -e splitbolt=6
