What ?
常用场景
- 系统间的解耦合
- 峰值压力缓冲
- 异步(并行)通信
- 常规的消息系统
- 不能保证绝对可靠
其它同类产品
- Rabit MQ
- Redis
- ZeroMQ
- ActiveMQ
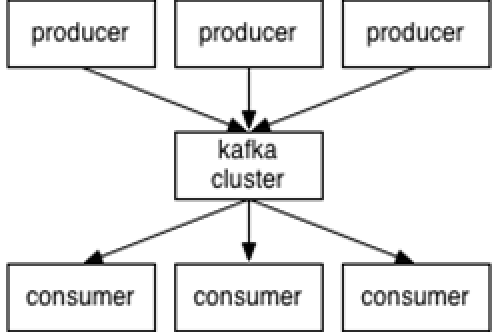
producer: 消息生产者
Producer将消息发布到之规定的topic中,同时producer也能决定将此消息归属于哪个partition
consumer:消费者
一个consumer属于一个consumer group 需要保存消费 消息的offset,对于offset的保存和使用,有消 费者consumer来控制 当consumer正常消费消 息时,offset将会"线性"的向前驱动,即消息将 依次顺序被消费
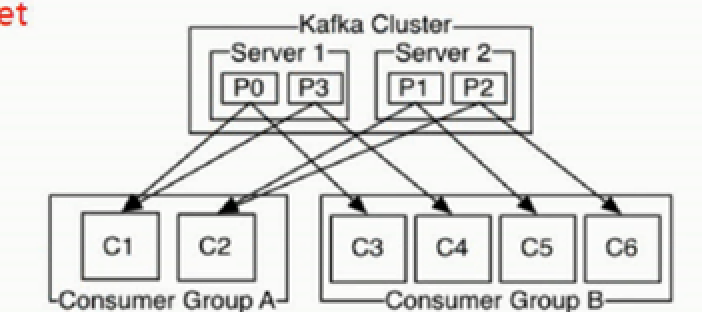
group
- 每个consumer都有对应的group
- 各个consumer消费不同的partition
- 因此一个消息在group内只消费一次
broker
kafka 集群的server服务,负责处理消息的读写请求,存储消息
topic
- 一个topic 可以认为是一类消息
- 一个topic 分成多个partition
- 每个partition内部消息强有序
- 消息不经过内存缓冲
- 根据时间策略 7天 删除
partitions
kafka基于文件存储.通过分区,可以将日志内容分散到多个server上,来避免文件尺寸达到单机磁盘的上限,每个partiton都会被当前server(kafka实例)保存;可以将一个topic切分多任意多个partitions,来消息保存/消费的效率.此外越多的partitions意味着可以容纳更多的consumer,有效提升并发消费的能力.
ISR
in-synco replicas 候选人机制 同步延后
Why ?
消息系统的特点
- 高性能
- 有序 FIFO 先进先出
- 持久性
- 持久化到磁盘且性能好
- 采用零拷贝技术
- 顺序读取
- 分布式
- 所有构件可以分布式
- 很灵活
- 高吞吐
- 单节点支持上千个客户端,百兆/s
Where?
http://kafka.apache.org/
How?
wget http://mirror.bit.edu.cn/apache/kafka/0.10.1.0/kafka_2.10-0.10.1.0.tgz
/opt/soft/kafka_2.10-0.10.1.0.tgz
tar zxvf kafka_2.10-0.9.0.1.tgz
cd /opt/soft/kafka_2.10-0.9.0.1
vi config/server.properties
修改zookeeper对应地址
zookeeper.connect=sj-node1:2181,sj-node3:2181,sj-node3:2181
scp -r kafka_2.10-0.9.0.1 root@sj-node2:/opt/soft/
scp -r kafka_2.10-0.9.0.1 root@sj-node3:/opt/soft/
scp -r kafka_2.10-0.9.0.1 root@sj-node3:/opt/soft/
分别修改 broker.id 从0开始 后面 分别是 1, 2, 3,4
修改完配置以后在每个节点启动kafka
bin/kafka-server-start.sh config/server.properties
测试
- 新建一个topic
./bin/kafka-topics.sh -zookeeper sj-node1:2181,sj-node2:2181,sj-node3:2181 -topic test -replication-factor 2 -partitions 5 --create - 查看当前的topic
./bin/kafka-topics.sh -zookeeper sj-node1:2181,sj-node2:2181,sj-node3:2181 -list - 在一个节点创建一个provider
./bin/kafka-console-producer.sh --broker-list sj-node1:9092,sj-node2:9092,sj-node3:9092 --topic test - 在另外一个节点创建一个consumer
./bin/kafka-console-consumer.sh --zookeeper sj-node1:2181,sj-node2:2181,sj-node3:2181 --from-beginning -topic test - 删除topic,不会立即生效
./bin/kafka-topics.sh --delete --topic test --zookeeper sj-node1:2181,sj-node2:2181,sj-node3:2181 - 查看明细
./bin/kafka-topics.sh --zookeeper sj-node1:2181 --describe --topic testflume
问题
- kafka offset 维护
- zookeeper维护 0.9版本以前
- kafka自己维护 0.9版本以后
- kafka offset 数据存储机制
- https://www.cnblogs.com/ITtangtang/p/8027217.html
彻底删除Kafka中的topic
- 删除kafka存储目录(server.properties文件log.dirs配置,默认为"/tmp/kafka-logs")相关topic目录
- Kafka 删除topic的命令是:
./bin/kafka-topics.sh --delete --zookeeper 【zookeeper server】 --topic 【topic name】
如果kafaka启动时加载的配置文件中server.properties没有配置delete.topic.enable=true,那么此时的删除并不是真正的删除,而是把topic标记为:marked for deletion
- 此时你若想真正删除它,可以登录zookeeper客户端: 命令:./bin/zookeeper-client 找到topic所在的目录:ls /brokers/topics 找到要删除的topic,执行命令:rmr /brokers/topics/【topic name】即可,此时topic被彻底删除。
问题
- 数据丢失
- procedure端 只有一个主机,接收数据保存在内存,如果死机,该段时间数据丢失 可以用个备份主机,发送方 ack机制 0:只发送不管leader接收是否成功,1:leader接收成功就下一条,-1:等所有备份机接收成功才下一条
- consumer端 如果是低级api,更新偏移量之后,执行的代码错误,导致该条数据未正常处理,如果是高级api,处理时间大于自动提交时间,则至少有一条丢失 解决方式:关闭自动提交,改成手动提交
- 数据重复消费 0.8版本默认是自动60s提交一次偏移量,如果在自动提交之前出错,已经处理过的偏移量未更新,则下次执行的时候会把那60s内处理过的数据再消费一次 解决方式:关闭自动提交,改成手动提交
