What
分布式离线计算框架 MapReduce On YARN:MRv2
- 移动计算而不是移动数据
- 一主多从架构
- JobTracker
- TaskTracker
- NameNode
- DateNode
- ResourceManager 负责整个集群的资源管理和`调度
- container
- 一个container一个进程
- container
- ApplicationMaster:负责应用程序相关的事务,比如任务调度、任务监控和容错等。
将MapReduce作业直接运行在YARN上,而不是由JobTracker和TaskTracker构建的MRv1系统中
-
基本功能模块
- YARN:负责资源管理和调度
- MRAppMaster:负责任务切分、任务调度、任务监控和容错等
- MapTask/ReduceTask:任务驱动引擎,与MRv1一致
-
每个MapRduce作业对应一个MRAppMaster任务调度
- YARN将资源分配给MRAppMaster
- MRAppMaster进一步将资源分配给内部的任务
-
MRAppMaster容错
- 失败后,由YARN重新启动
- 任务失败后,MRAppMaster重新申请资源
-
Zookeeper Failover Controller: 监控NameNode健康状态,并向Zookeeper注册NameNode,NameNode挂掉后,ZKFC为NameNode竞争锁,获得ZKFC 锁的NameNode变为active
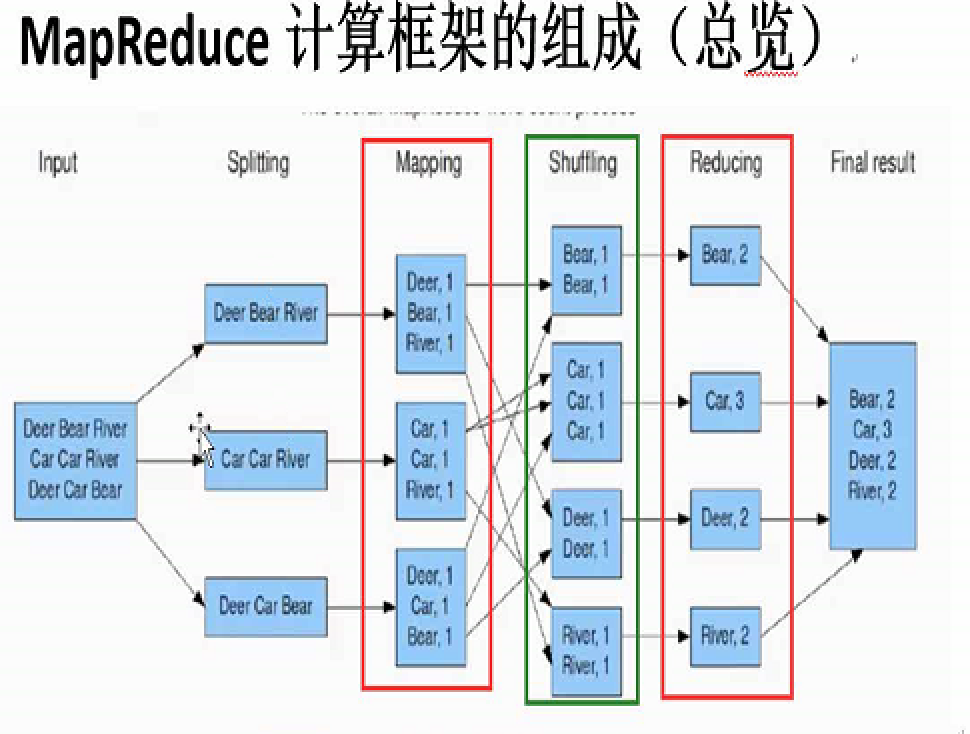
细节
- input split 对应一个 block 128M
- output 可能大于 一个block 128M
- map 到 reduce 方法之间 叫 shuffle
- map 在相应的datanode上执行,reduce找空闲的datanode执行,不一定在block上
- split后的大小不一定是一个block大小
- map的输出物是经过快速排序的
<div id="flowchart-0" class="flow-chart"></div>
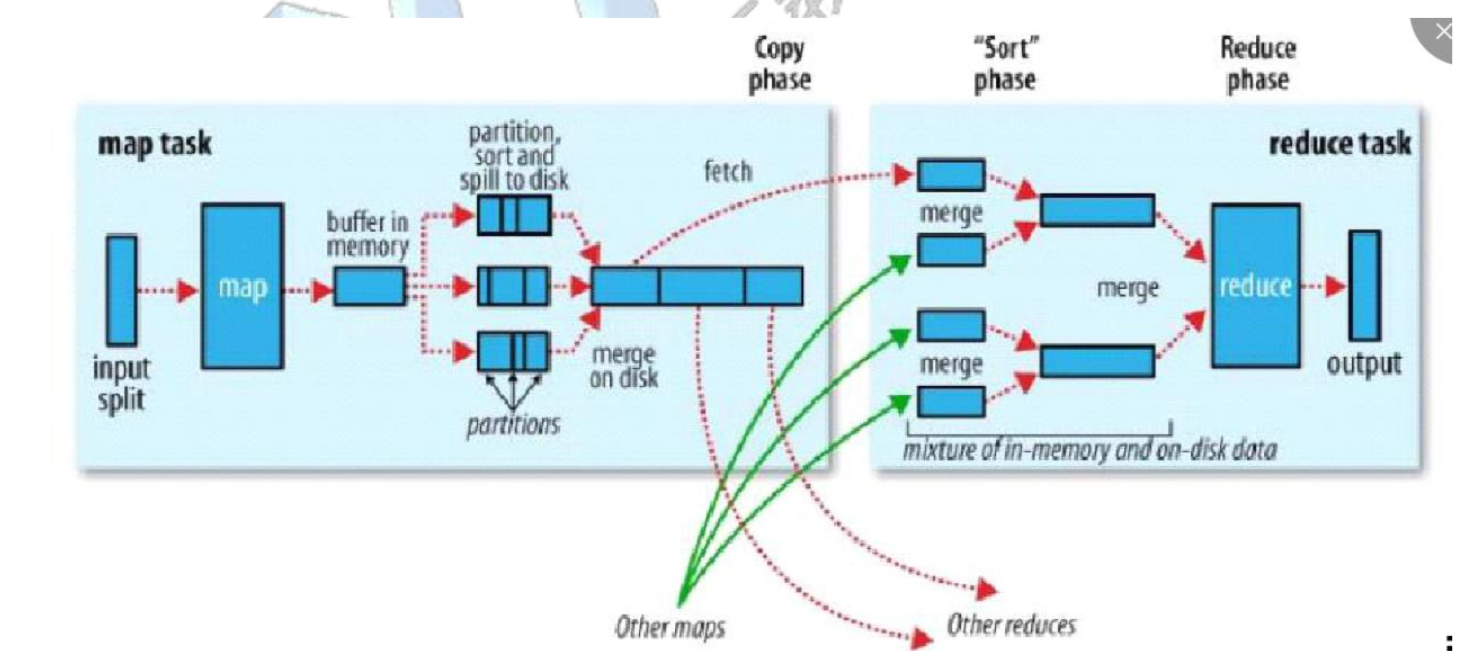
partition
- hash(key) mod r
- 有几个reduce 就有几个partition
shuffle
map task <div id="flowchart-1" class="flow-chart"></div>
Why
海量数据计算
Where
http://hadoop.apache.org/docs/r2.5.2/hadoop-yarn/hadoop-yarn-site/ResourceManagerHA.html http://www.cnblogs.com/luogankun/p/4019303.html https://note.youdao.com/share/?id=95d458d779f8e9f391d6ea06b6c6d122&type=note#/ https://note.youdao.com/share/?id=86ca5c96d13413f789164ff92f9ab4f9&type=note#/ https://note.youdao.com/share/?id=212e4a69d7bf8fc30979f1e4fc39ff0f&type=note#/ https://note.youdao.com/share/?id=a518dfed10d824b0995380669ddd28c9&type=note#/
How
-
配置文件yarn-site.xml
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30<configuration>
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value>appcity</value>
</property>
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm1</name>
<value>sj-node3</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm2</name>
<value>sj-node4</value>
</property>
<property>
<name>yarn.resourcemanager.zk-address</name>
<value>sj-node1:2181,sj-node2:2181,sj-node3:2181</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration> -
配置mapred-site.xml使用yarn来调度
cp etc/hadoop/mapred-site.xml.template etc/hadoop/mapred-site.xmlvi etc/hadoop/mapred-site.xml1
2
3
4
5
6<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration> -
将配置文件拷贝到其它机器上
1
2
3
4
5
6scp etc/hadoop/yarn-site.xml sj-node2:/opt/soft/hadoop-2.5.1/etc/hadoop/
scp etc/hadoop/yarn-site.xml sj-node3:/opt/soft/hadoop-2.5.1/etc/hadoop/
scp etc/hadoop/yarn-site.xml sj-node4:/opt/soft/hadoop-2.5.1/etc/hadoop/
scp etc/hadoop/mapred-site.xml sj-node2:/opt/soft/hadoop-2.5.1/etc/hadoop/
scp etc/hadoop/mapred-site.xml sj-node3:/opt/soft/hadoop-2.5.1/etc/hadoop/
scp etc/hadoop/mapred-site.xml sj-node4:/opt/soft/hadoop-2.5.1/etc/hadoop/ -
由于配置了3,4节点为yarn的主节点,所以进入3或4执行命令
./sbin/start-yarn.sh -
如果某个节点故障 kill掉之后 执行单独启动命令
./sbin/yarn-daemon.sh start resourcemanager -
检查 http://sj-node3:8088/cluster 能够访问代表主节点启动成功 http://sj-node4:8088/cluster 能够访问并自动跳转到node3代表热备机启动成功
 <script src="https://cdnjs.cloudflare.com/ajax/libs/raphael/2.2.7/raphael.min.js"></script><script src="https://cdnjs.cloudflare.com/ajax/libs/flowchart/1.6.5/flowchart.min.js"></script>
<script src="https://cdnjs.cloudflare.com/ajax/libs/raphael/2.2.7/raphael.min.js"></script><script src="https://cdnjs.cloudflare.com/ajax/libs/flowchart/1.6.5/flowchart.min.js"></script>
