What
Hadoop 2.x由HDFS、MapReduce和YARN三个分支构
- HDFS:分布式文件存储系统;
- YARN:资源管理系统
- MapReduce:运行在YARN上的MR;
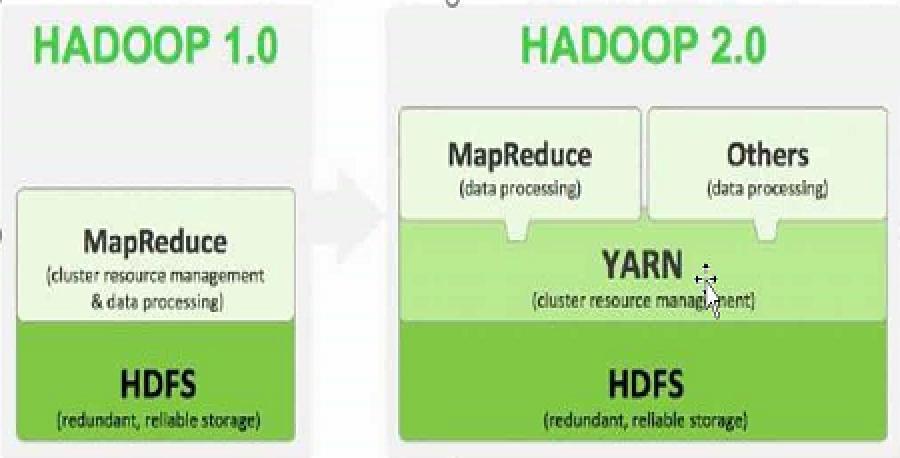
Hadoop 2.0产生背景
- Hadoop 1.0中HDFS和MapReduce在高可用、扩展性等方面存在问题。
- HDFS存在的问题
- NameNode单点故障,难以应用于在线场景
- NameNode压力过大,且内存受限,影响系统扩展性
- MapReduce存在的问题
- JobTracker访问压力大,影响系统扩展性
- 难以支持除MapReduce之外的计算框架,比如Spark、Storm等.
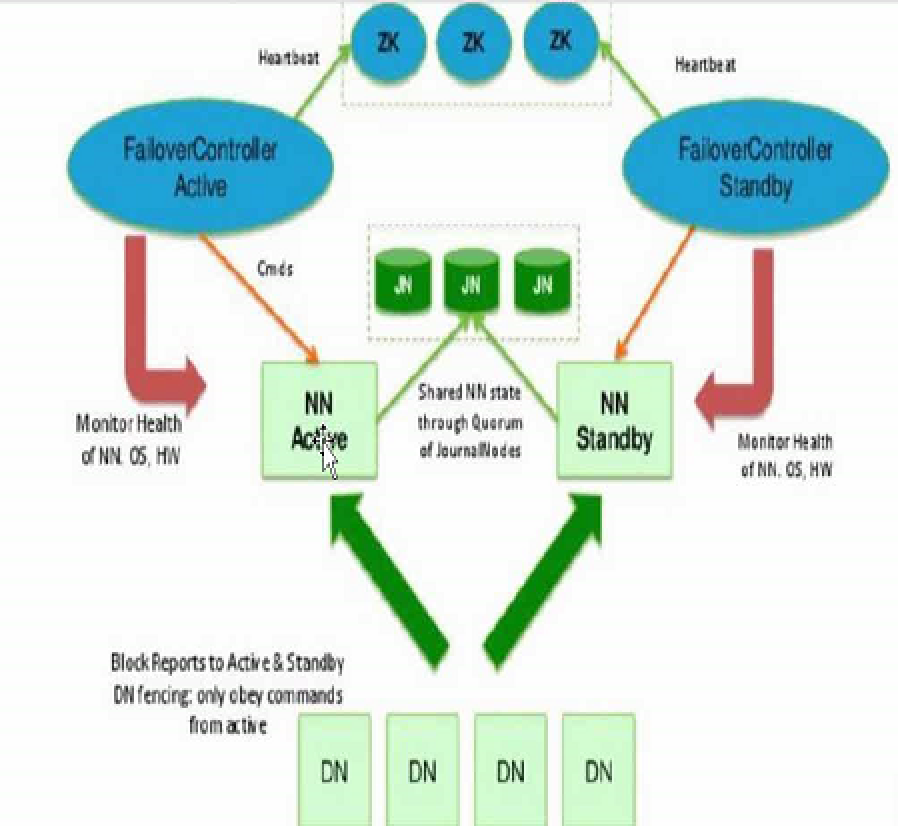
Yarn
资源管理系统 ,由jobTracker 演化而来
- 资源管理 ResourceManager
- 任务调度 ApplicationMaster
资源管理调度流程
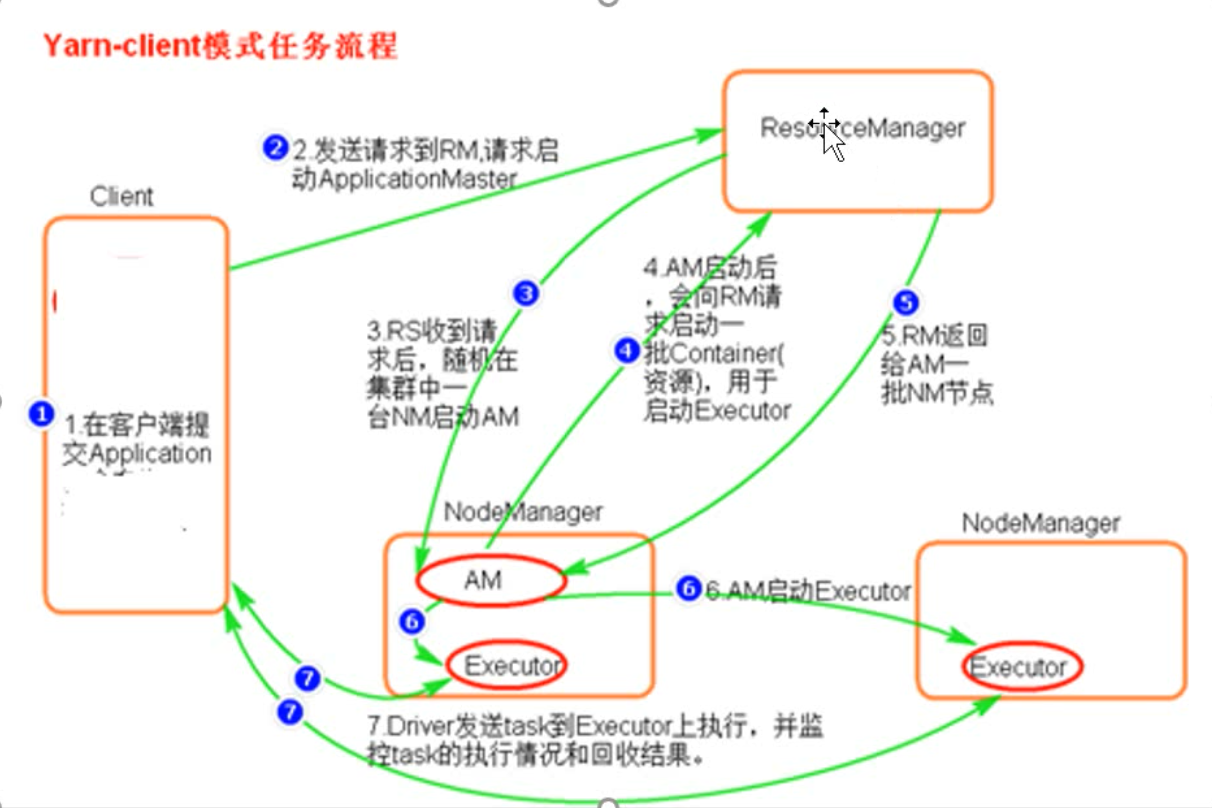
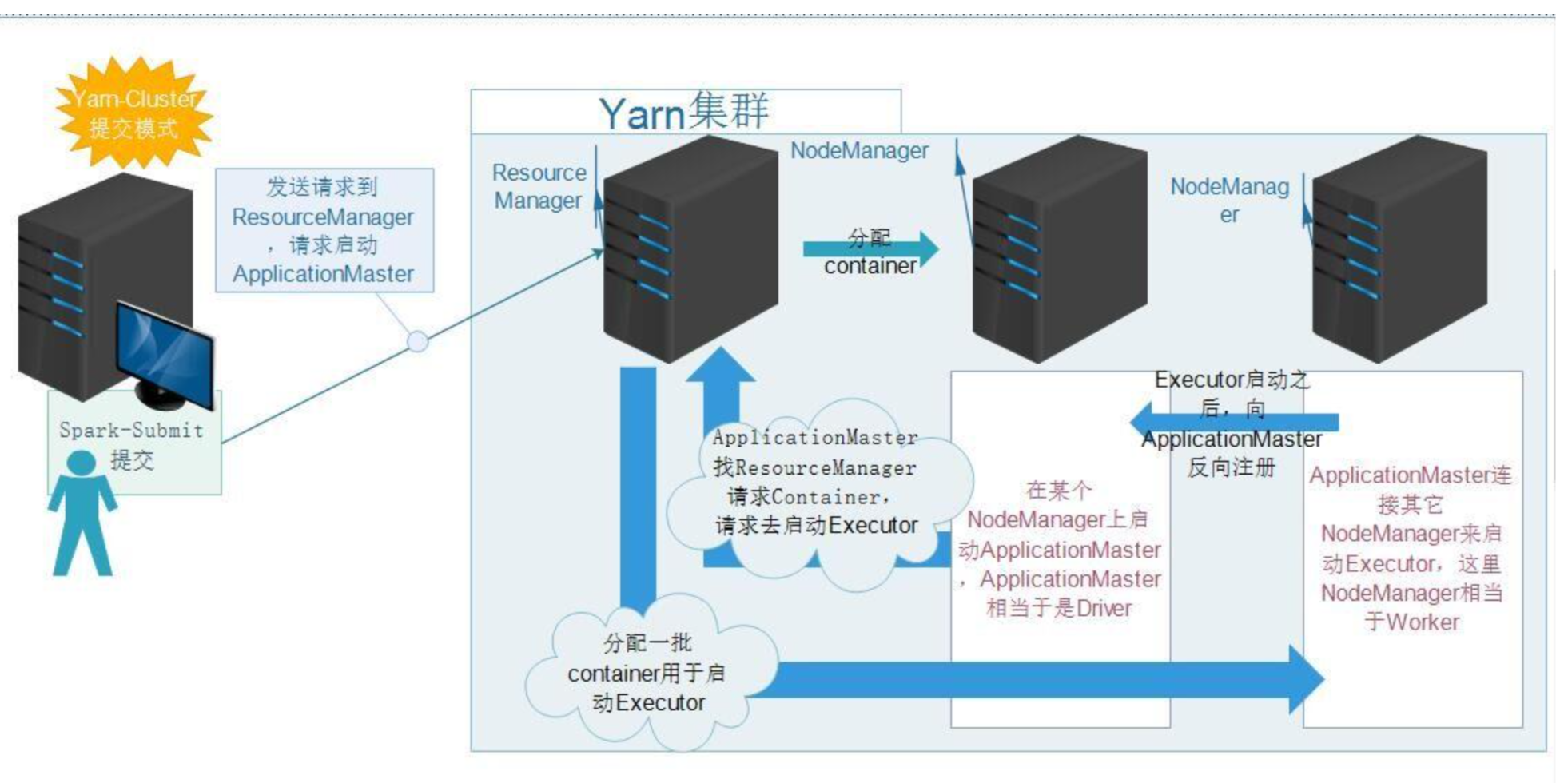
流程大致如下
- client客户端向yarn集群(resourcemanager)提交任务
- resourcemanager选择一个node创建appmaster
- appmaster根据任务向rm申请资源
- rm返回资源申请的结果
- appmaster去对应的node上创建任务需要的资源(container形式,包括内存和CPU)
- appmaster负责与nodemanager进行沟通,监控任务运行
- 最后任务运行成功,汇总结果。
- 其中Resourcemanager里面一个很重要的东西,就是调度器Scheduler,调度规则可以使用官方提供的,也可以自定义。
Where
http://hadoop.apache.org/docs/r2.5.2/hadoop-project-dist/hadoop-hdfs/HDFSHighAvailabilityWithQJM.html
Why
- zookeeper 选举机制
How
-
hdfs-site.xml
cd /opt/soft/hadoop-2.5.1/vi etc/hadoop/hdfs-site.xml1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48<property>
<name>dfs.nameservices</name>
<value>appcity</value>
</property>
<property>
<name>dfs.ha.namenodes.appcity</name>
<value>nn1,nn2</value>
</property>
<property>
<name>dfs.namenode.rpc-address.appcity.nn1</name>
<value>sj-node1:8020</value>
</property>
<property>
<name>dfs.namenode.rpc-address.appcity.nn2</name>
<value>sj-node2:8020</value>
</property>
<property>
<name>dfs.namenode.http-address.appcity.nn1</name>
<value>sj-node1:50070</value>
</property>
<property>
<name>dfs.namenode.http-address.appcity.nn2</name>
<value>sj-node2:50070</value>
</property>
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://sj-node2:8485;sj-node2:8485;sj-node4:8485/appcity</value>
</property>
<property>
<name>dfs.client.failover.proxy.provider.appcity</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
</property>
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/root/.ssh/id_dsa</value>
</property>
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/opt/soft/hadoop-2.5.1/data/jn</value>
</property>
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property> -
core-site.xml
vim etc/hadoop/core-site.xml1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26<property>
<name>fs.defaultFS</name>
<value>hdfs://appcity</value>
</property>
<property>
<name>fs.default.name</name>
<value>hdfs://appcity</value>
</property>
<property>
<name>ha.zookeeper.quorum</name>
<value>sj-node2:2181,sj-node3:2181,sj-node4:2181</value>
</property>
<property>
<name>ipc.client.connect.max.retries</name>
<value>100</value>
<description>Indicates the number of retries a client will make to establish
a server connection.
</description>
</property>
<property>
<name>ipc.client.connect.retry.interval</name>
<value>1000</value>
<description>Indicates the number of milliseconds a client will wait for
before retrying to establish a server connection.
</description>
</property> -
复制配置文件
1
2
3
4
5
6scp etc/hadoop/hdfs-site.xml sj-node2:/opt/soft/hadoop-2.5.1/etc/hadoop/
scp etc/hadoop/hdfs-site.xml sj-node3:/opt/soft/hadoop-2.5.1/etc/hadoop/
scp etc/hadoop/hdfs-site.xml sj-node4:/opt/soft/hadoop-2.5.1/etc/hadoop/
scp etc/hadoop/core-site.xml sj-node2:/opt/soft/hadoop-2.5.1/etc/hadoop/
scp etc/hadoop/core-site.xml sj-node3:/opt/soft/hadoop-2.5.1/etc/hadoop/
scp etc/hadoop/core-site.xml sj-node4:/opt/soft/hadoop-2.5.1/etc/hadoop/ -
删除masters
cp ./etc/hadoop/masters ./etc/hadoop/masters.bakrm ./etc/hadoop/masters -
删除之前存储的一些元信息和数据 譬如/opt/hadoop
rm -rf data/dfs/ -
启动JNs 至少三个节点 分别在2,3,4节点执行
./sbin/hadoop-daemon.sh start journalnode -
在其中一个namenode所在的节点来执行
./bin/hdfs namenode -format -
把刚才格式化好的那个namenode启动起来
./sbin/hadoop-daemon.sh start namenode -
在另外的其他你配置的namenode上面去执行
./bin/hdfs namenode -bootstrapStandby -
把刚才第8步启动那个namenode先停掉
./sbin/hadoop-daemon.sh stop namenode -
启动ZK集群 3台机器上执行
/opt/soft/zookeeper-3.4.8/bin/zkServer.sh start -
在其中某一台namenode节点上面来完成
./bin/hdfs zkfc -formatZK -
在其中某一台namenode节点上面来完成 启动集群
./sbin/start-dfs.sh -
启动在3或4节点上启动yarn
yarn-daemon.sh start resourcemanager
有可能会出错的地方
- 确认每台机器防火墙均关掉
- 确认每台机器的时间是一致的
- 确认配置文件无误,并且确认每台机器上面的配置文件一样
- 如果还有问题想重新格式化,那么先把所有节点的进程关掉
- 删除之前格式化的数据目录hadoop.tmp.dir属性对应的目录,所有节点同步都删掉,别单删掉之前的一个,删掉三台JN节点中dfs.journalnode.edits.dir属性所对应的目录
- 接上面的第6步又可以重新格式化已经启动了
- 最终Active Namenode停掉的时候,StandBy可以自动接管!
脑裂(brain-split)
脑裂是指在主备切换时,由于切换不彻底或其他原因,导致客户端和Slave误以为出现两个active master,最终使得整个集群处于混乱状态。解决脑裂问题,通常采用隔离(Fencing)机制,包括三个方面:
- 共享存储fencing:确保只有一个Master往共享存储中写数据。
- 客户端fencing:确保只有一个Master可以响应客户端的请求。
- Slave fencing:确保只有一个Master可以向Slave下发命令。
Hadoop公共库中对外提供了两种fenching实现,分别是sshfence和shellfence(缺省实现),其中sshfence是指通过ssh登陆目标Master节点上,使用命令fuser将进程杀死(通过tcp端口号定位进程pid,该方法比jps命令更准确),shellfence是指执行一个用户事先定义的shell命令(脚本)完成隔离。
参考
- https://blog.csdn.net/oaimm/article/details/38336089 问题
- hdfs权限问题
- 动namenode失败,Error replaying edit
